GEMM AVX512
Я сьогодні розкажу історію про множення матриць. Всі ви знаєте шо існує багато BLAS варіантів, наприклад той BLAS шо у вас в Apple Watch cblas_dgemm і той BLAS шо у вас на Linux в OpenBLAS cblas_dgemm і той шо у вас в GROMACS на Xeon --- це різні функції мультиплікації матриць.
Топові суплаєри BLAS-ів на сьогодні це вирибники процесорів і науковці:
1) OpenBLAS
2) Apple BLAS
3) Intel MKL BLAS
Всі три інтерфейса сумісні і при лінковці можна вибрати з ким ви хочете лінкуватися. Математик шоб множити матриці повинен знати лінійну алгебру (факторизація, тензорне числення) і чисельні методи (похибки, сходимість, ефективність, граничність ефективності). Програміст крім цього ше повинен знати ієрархію кешів по латенсі і розуміти мотивацію створення векторних інструкцій процесорів. Тому ця стаття присвячена висвітленню цього питання. Отже почнемо з найсучаснішого BLAS від Intel який зараз постачається як oneAPI Math Kernel Library і покажемо як використовувати cblas_dgenv в коді.
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include "utils.h"
#include "mkl.h"
int main(int argc, char *argv[])
{
int m = 2000, n = 2000, kernel_num = 2;
double *A, *X, *Y, *R, t0, t1, elapsed_time;
printf("Testing MKL DGEMV.\n");
printf("m = %d, n = %d.\n", m, n);
A = (double*)malloc(sizeof(double) * m * n);
X = (double*)malloc(sizeof(double) * n);
Y = (double*)malloc(sizeof(double) * m);
R = (double*)malloc(sizeof(double) * m);
double alpha = 1., beta = 1.; int N = 5;
randomize_matrix(A, m, n); randomize_matrix(X, n, 1); randomize_matrix(Y, m, 1);
copy_matrix(Y, R, m);
t0 = get_sec();
for (int i = 0; i < N; i++) {
cblas_dgemv(CblasRowMajor, CblasNoTrans, m, n, alpha, A, n, X, 1, beta, Y, 1);
}
elapsed_time = get_sec() - t0;
printf("Average elasped time: %f second, performance: %f GFLOPS.\n", elapsed_time/N,2.*N*1e-9*m*n/elapsed_time);
free(A); free(X); free(Y); free(R);
return 0;
}
Нам знадобляться декілька джерел: 1) Архітектура і програмування процесорів Intel, 2) стаття "BLISlab: A Sandbox for Optimizing GEMM", 3) стаття "Anatomy of high-performance matrix multiplication"
[1]. Intel PDF
[2]. BLISlab: A Sandbox for Optimizing GEMM
[3]. Anatomy of High-Performance Matrix
Multiplication
Почнемо писати своє множення матриць аби показати покроково всі кроки оптимізації, почнемо з ідіоматичного множення яке малюють викладачі в школі:
#define A(i,j) A[(i)+(j)*LDA]
#define B(i,j) B[(i)+(j)*LDB]
#define C(i,j) C[(i)+(j)*LDC]
void scale_c_k1(double *C,int M, int N, int LDC, double scalar){
int i,j;
for (i=0;i<M;i++){
for (j=0;j<N;j++){
C(i,j)*=scalar;
}
}
}
void mydgemm_cpu_v1(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
int i,j,k;
if (beta != 1.0) scale_c_k1(C,M,N,LDC,beta);
for (i=0;i<M;i++){
for (j=0;j<N;j++){
for (k=0;k<K;k++){
C(i,j) += alpha*A(i,k)*B(k,j);
}
}
}
}Тут вже можна побачити шо C(i,j) не залежить від K тому можна оптимізувати блокування шини адресу для інструкцій по пам'яті і перенести внутрішній цикл в регістр (змінна tmp):
void scale_c_k2(double *C,int M, int N, int LDC, double scalar){
int i,j;
for (i=0;i<M;i++){
for (j=0;j<N;j++){
C(i,j)*=scalar;
}
}
}
void mydgemm_cpu_v2(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
int i,j,k;
if (beta != 1.0) scale_c_k2(C,M,N,LDC,beta);
for (i=0;i<M;i++){
for (j=0;j<N;j++){
double tmp=C(i,j);
for (k=0;k<K;k++){
tmp += alpha*A(i,k)*B(k,j);
}
C(i,j) = tmp;
}
}
}
Далі ми розбиваємо матрицю на два рекурсивних блоки для цього забираємо по 2 подвійних дійсних слова з зовнішніх циклів і в середині робимо векторний контейнер на 4 подвійних дійсних слова.
void mydgemm_cpu_v3(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
int i,j,k;
if (beta != 1.0) scale_c_k3(C,M,N,LDC,beta);
int M2=M&-2,N2=N&-2;
for (i=0;i<M2;i+=2){
for (j=0;j<N2;j+=2){
double c00=C(i,j);
double c01=C(i,j+1);
double c10=C(i+1,j);
double c11=C(i+1,j+1);
for (k=0;k<K;k++){
double a0 = alpha*A(i,k);
double a1 = alpha*A(i+1,k);
double b0 = B(k,j);
double b1 = B(k,j+1);
c00 += a0*b0;
c01 += a0*b1;
c10 += a1*b0;
c11 += a1*b1;
}
C(i,j) = c00;
C(i,j+1) = c01;
C(i+1,j) = c10;
C(i+1,j+1) = c11;
}
}
if (M2==M&&N2==N) return;
// boundary conditions
if (M2!=M) mydgemm_cpu_opt_k3(M-M2,N,K,alpha,A+M2,LDA,B,LDB,1.0,&C(M2,0),LDC);
if (N2!=N) mydgemm_cpu_opt_k3(M2,N-N2,K,alpha,A,LDA,&B(0,N2),LDB,1.0,&C(0,N2),LDC);
}Наше завдання звести все до обчислення слайсів 2x1 в A і 1x2 в B і зробити обчислення C як зовнішній добуток першого рангу цілого блоку 2х2. Зверніть увагу на M-N-K неймінг рівнів циклів, у всіх пейперах вони такі самі. Потім ми збільшуємо кількість зовнішніх циклів в блоці до 16 (4х4):
void mydgemm_cpu_v4(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
int i,j,k;
if (beta != 1.0) scale_c_k4(C,M,N,LDC,beta);
int M4=M&-4,N4=N&-4;
for (i=0;i<M4;i+=4){
for (j=0;j<N4;j+=4){
double c00=C(i,j);
double c01=C(i,j+1);
double c02=C(i,j+2);
double c03=C(i,j+3);
double c10=C(i+1,j);
double c11=C(i+1,j+1);
double c12=C(i+1,j+2);
double c13=C(i+1,j+3);
double c20=C(i+2,j);
double c21=C(i+2,j+1);
double c22=C(i+2,j+2);
double c23=C(i+2,j+3);
double c30=C(i+3,j);
double c31=C(i+3,j+1);
double c32=C(i+3,j+2);
double c33=C(i+3,j+3);
for (k=0;k<K;k++){
double a0 = alpha*A(i,k);
double a1 = alpha*A(i+1,k);
double a2 = alpha*A(i+2,k);
double a3 = alpha*A(i+3,k);
double b0 = B(k,j);
double b1 = B(k,j+1);
double b2 = B(k,j+2);
double b3 = B(k,j+3);
c00 += a0*b0;
c01 += a0*b1;
c02 += a0*b2;
c03 += a0*b3;
c10 += a1*b0;
c11 += a1*b1;
c12 += a1*b2;
c13 += a1*b3;
c20 += a2*b0;
c21 += a2*b1;
c22 += a2*b2;
c23 += a2*b3;
c30 += a3*b0;
c31 += a3*b1;
c32 += a3*b2;
c33 += a3*b3;
}
C(i,j) = c00;
C(i,j+1) = c01;
C(i,j+2) = c02;
C(i,j+3) = c03;
C(i+1,j) = c10;
C(i+1,j+1) = c11;
C(i+1,j+2) = c12;
C(i+1,j+3) = c13;
C(i+2,j) = c20;
C(i+2,j+1) = c21;
C(i+2,j+2) = c22;
C(i+2,j+3) = c23;
C(i+3,j) = c30;
C(i+3,j+1) = c31;
C(i+3,j+2) = c32;
C(i+3,j+3) = c33;
}
}
if (M4==M&&N4==N) return;
// boundary conditions
if (M4!=M) mydgemm_cpu_opt_k4(M-M4,N,K,alpha,A+M4,LDA,B,LDB,1.0,&C(M4,0),LDC);
if (N4!=N) mydgemm_cpu_opt_k4(M4,N-N4,K,alpha,A,LDA,&B(0,N4),LDB,1.0,&C(0,N4),LDC);
}
Потім переписуємо на інтрінсіки
void mydgemm_cpu_v5(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
int i,j,k;
if (beta != 1.0) scale_c_k5(C,M,N,LDC,beta);
int M4=M&-4,N4=N&-4;
__m256d valpha = _mm256_set1_pd(alpha);//broadcast alpha to a 256-bit vector
for (i=0;i<M4;i+=4){
for (j=0;j<N4;j+=4){
__m256d c0 = _mm256_setzero_pd();
__m256d c1 = _mm256_setzero_pd();
__m256d c2 = _mm256_setzero_pd();
__m256d c3 = _mm256_setzero_pd();
for (k=0;k<K;k++){
__m256d a = _mm256_mul_pd(valpha, _mm256_loadu_pd(&A(i,k)));
__m256d b0 = _mm256_broadcast_sd(&B(k,j));
__m256d b1 = _mm256_broadcast_sd(&B(k,j+1));
__m256d b2 = _mm256_broadcast_sd(&B(k,j+2));
__m256d b3 = _mm256_broadcast_sd(&B(k,j+3));
c0 = _mm256_fmadd_pd(a,b0,c0);
c1 = _mm256_fmadd_pd(a,b1,c1);
c2 = _mm256_fmadd_pd(a,b2,c2);
c3 = _mm256_fmadd_pd(a,b3,c3);
}
_mm256_storeu_pd(&C(i,j), _mm256_add_pd(c0,_mm256_loadu_pd(&C(i,j))));
_mm256_storeu_pd(&C(i,j+1), _mm256_add_pd(c1,_mm256_loadu_pd(&C(i,j+1))));
_mm256_storeu_pd(&C(i,j+2), _mm256_add_pd(c2,_mm256_loadu_pd(&C(i,j+2))));
_mm256_storeu_pd(&C(i,j+3), _mm256_add_pd(c3,_mm256_loadu_pd(&C(i,j+3))));
}
}
if (M4==M&&N4==N) return;
// boundary conditions
if (M4!=M) mydgemm_cpu_opt_k5(M-M4,N,K,alpha,A+M4,LDA,B,LDB,1.0,&C(M4,0),LDC);
if (N4!=N) mydgemm_cpu_opt_k5(M4,N-N4,K,alpha,A,LDA,&B(0,N4),LDB,1.0,&C(0,N4),LDC);
}
Потім виносимо внутрішній цикл в макроси бо там насправді нам доведеться робити патерн мачінг (кейс аналіз) по варіантам зображеним на другому малюнку
#define KERNEL_K1_4x4_avx2_intrinsics\
a = _mm256_mul_pd(valpha, _mm256_loadu_pd(&A(i,k)));\
b0 = _mm256_broadcast_sd(&B(k,j));\
b1 = _mm256_broadcast_sd(&B(k,j+1));\
b2 = _mm256_broadcast_sd(&B(k,j+2));\
b3 = _mm256_broadcast_sd(&B(k,j+3));\
c0 = _mm256_fmadd_pd(a,b0,c0);\
c1 = _mm256_fmadd_pd(a,b1,c1);\
c2 = _mm256_fmadd_pd(a,b2,c2);\
c3 = _mm256_fmadd_pd(a,b3,c3);\
k++;
#define KERNEL_K1_4x1_avx2_intrinsics\
a = _mm256_mul_pd(valpha, _mm256_loadu_pd(&A(i,k)));\
b0 = _mm256_broadcast_sd(&B(k,j));\
c0 = _mm256_fmadd_pd(a,b0,c0);\
k++;
void mydgemm_cpu_v6(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
int i,j,k;
if (beta != 1.0) scale_c_k6(C,M,N,LDC,beta);
int M4=M&-4,N4=N&-4,K4=K&-4;
__m256d valpha = _mm256_set1_pd(alpha);//broadcast alpha to a 256-bit vector
__m256d a,b0,b1,b2,b3;
for (i=0;i<M4;i+=4){
for (j=0;j<N4;j+=4){
__m256d c0 = _mm256_setzero_pd();
__m256d c1 = _mm256_setzero_pd();
__m256d c2 = _mm256_setzero_pd();
__m256d c3 = _mm256_setzero_pd();
// unroll the loop by four times
for (k=0;k<K4;){
KERNEL_K1_4x4_avx2_intrinsics
KERNEL_K1_4x4_avx2_intrinsics
KERNEL_K1_4x4_avx2_intrinsics
KERNEL_K1_4x4_avx2_intrinsics
}
// deal with the edge case for K
for (k=K4;k<K;){
KERNEL_K1_4x4_avx2_intrinsics
}
_mm256_storeu_pd(&C(i,j), _mm256_add_pd(c0,_mm256_loadu_pd(&C(i,j))));
_mm256_storeu_pd(&C(i,j+1), _mm256_add_pd(c1,_mm256_loadu_pd(&C(i,j+1))));
_mm256_storeu_pd(&C(i,j+2), _mm256_add_pd(c2,_mm256_loadu_pd(&C(i,j+2))));
_mm256_storeu_pd(&C(i,j+3), _mm256_add_pd(c3,_mm256_loadu_pd(&C(i,j+3))));
}
}
if (M4==M&&N4==N) return;
// boundary conditions
if (M4!=M) mydgemm_cpu_opt_k6(M-M4,N,K,alpha,A+M4,LDA,B,LDB,1.0,&C(M4,0),LDC);
if (N4!=N) mydgemm_cpu_opt_k6(M4,N-N4,K,alpha,A,LDA,&B(0,N4),LDB,1.0,&C(0,N4),LDC);
}
Від попереднього 4х4 блоку пи збільшуємо об'єми векторних обчислень і укрупняємо до 8х4
#define KERNEL_K1_8x4_avx2_intrinsics\
a0 = _mm256_mul_pd(valpha, _mm256_loadu_pd(&A(i,k)));\
a1 = _mm256_mul_pd(valpha, _mm256_loadu_pd(&A(i+4,k)));\
b0 = _mm256_broadcast_sd(&B(k,j));\
b1 = _mm256_broadcast_sd(&B(k,j+1));\
b2 = _mm256_broadcast_sd(&B(k,j+2));\
b3 = _mm256_broadcast_sd(&B(k,j+3));\
c00 = _mm256_fmadd_pd(a0,b0,c00);\
c01 = _mm256_fmadd_pd(a1,b0,c01);\
c10 = _mm256_fmadd_pd(a0,b1,c10);\
c11 = _mm256_fmadd_pd(a1,b1,c11);\
c20 = _mm256_fmadd_pd(a0,b2,c20);\
c21 = _mm256_fmadd_pd(a1,b2,c21);\
c30 = _mm256_fmadd_pd(a0,b3,c30);\
c31 = _mm256_fmadd_pd(a1,b3,c31);\
k++;
void mydgemm_cpu_v7(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
int i,j,k;
if (beta != 1.0) scale_c_k7(C,M,N,LDC,beta);
int M8=M&-8,N4=N&-4,K4=K&-4;
__m256d valpha = _mm256_set1_pd(alpha);//broadcast alpha to a 256-bit vector
__m256d a0,a1,b0,b1,b2,b3;
for (i=0;i<M8;i+=8){
for (j=0;j<N4;j+=4){
__m256d c00 = _mm256_setzero_pd();
__m256d c01 = _mm256_setzero_pd();
__m256d c10 = _mm256_setzero_pd();
__m256d c11 = _mm256_setzero_pd();
__m256d c20 = _mm256_setzero_pd();
__m256d c21 = _mm256_setzero_pd();
__m256d c30 = _mm256_setzero_pd();
__m256d c31 = _mm256_setzero_pd();
// unroll the loop by four times
for (k=0;k<K4;){
KERNEL_K1_8x4_avx2_intrinsics
KERNEL_K1_8x4_avx2_intrinsics
KERNEL_K1_8x4_avx2_intrinsics
KERNEL_K1_8x4_avx2_intrinsics
}
// deal with the edge case for K
for (k=K4;k<K;){
KERNEL_K1_8x4_avx2_intrinsics
}
_mm256_storeu_pd(&C(i,j), _mm256_add_pd(c00,_mm256_loadu_pd(&C(i,j))));
_mm256_storeu_pd(&C(i+4,j), _mm256_add_pd(c01,_mm256_loadu_pd(&C(i+4,j))));
_mm256_storeu_pd(&C(i,j+1), _mm256_add_pd(c10,_mm256_loadu_pd(&C(i,j+1))));
_mm256_storeu_pd(&C(i+4,j+1), _mm256_add_pd(c11,_mm256_loadu_pd(&C(i+4,j+1))));
_mm256_storeu_pd(&C(i,j+2), _mm256_add_pd(c20,_mm256_loadu_pd(&C(i,j+2))));
_mm256_storeu_pd(&C(i+4,j+2), _mm256_add_pd(c21,_mm256_loadu_pd(&C(i+4,j+2))));
_mm256_storeu_pd(&C(i,j+3), _mm256_add_pd(c30,_mm256_loadu_pd(&C(i,j+3))));
_mm256_storeu_pd(&C(i+4,j+3), _mm256_add_pd(c31,_mm256_loadu_pd(&C(i+4,j+3))));
}
}
if (M8==M&&N4==N) return;
// boundary conditions
if (M8!=M) mydgemm_cpu_opt_k7(M-M8,N,K,alpha,A+M8,LDA,B,LDB,1.0,&C(M8,0),LDC);
if (N4!=N) mydgemm_cpu_opt_k7(M8,N-N4,K,alpha,A,LDA,&B(0,N4),LDB,1.0,&C(0,N4),LDC);
}
Щоб уникнути промахів TLB під час доступу до блоків кешу, ми пакуємо блоки даних у неперервну пам’ять перед їх завантаженням. Це драматікалі покращує ситуацію:
void packing_a_k9(double *src, double *dst, int leading_dim, int dim_first, int dim_second){
//dim_first: M, dim_second: K
double *tosrc,*todst;
todst=dst;
int count_first,count_second,count_sub=dim_first;
for (count_first=0;count_sub>7;count_first+=8,count_sub-=8){
tosrc=src+count_first;
for(count_second=0;count_second<dim_second;count_second++){
_mm512_store_pd(todst,_mm512_loadu_pd(tosrc));
tosrc+=leading_dim;
todst+=8;
}
}
for (;count_sub>3;count_first+=4,count_sub-=4){
tosrc=src+count_first;
for(count_second=0;count_second<dim_second;count_second++){
_mm256_store_pd(todst,_mm256_loadu_pd(tosrc));
tosrc+=leading_dim;
todst+=4;
}
}
}
void packing_b_k9(double *src,double *dst,int leading_dim,int dim_first,int dim_second){
//dim_first:K,dim_second:N
double *tosrc1,*tosrc2,*tosrc3,*tosrc4,*todst;
todst=dst;
int count_first,count_second;
for (count_second=0;count_second<dim_second;count_second+=4){
tosrc1=src+count_second*leading_dim;tosrc2=tosrc1+leading_dim;
tosrc3=tosrc2+leading_dim;tosrc4=tosrc3+leading_dim;
for (count_first=0;count_first<dim_first;count_first++){
*todst=*tosrc1;tosrc1++;todst++;
*todst=*tosrc2;tosrc2++;todst++;
*todst=*tosrc3;tosrc3++;todst++;
*todst=*tosrc4;tosrc4++;todst++;
}
}
}
Збираємо докупи варінт з 4х4 блоком і 8х4 блоком:
void macro_kernel_gemm_k9(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double *C, int LDC){
int i,j,k;
int M8=M&-8,N4=N&-4,K4=K&-4;
double *ptr_packing_a = A;
double *ptr_packing_b = B;
__m256d valpha = _mm256_set1_pd(alpha);//broadcast alpha to a 256-bit vector
__m256d a,a0,a1,b0,b1,b2,b3;
__m256d c00,c01,c10,c11,c20,c21,c30,c31;
__m256d c0,c1,c2,c3;
for (i=0;i<M8;i+=8){
for (j=0;j<N4;j+=4){
ptr_packing_a=A+i*K;ptr_packing_b=B+j*K;
macro_kernel_8xkx4_packing
}
}
for (i=M8;i<M;i+=4){
for (j=0;j<N4;j+=4){
ptr_packing_a=A+i*K;ptr_packing_b=B+j*K;
macro_kernel_4xkx4_packing
}
}
}
void mydgemm_cpu_v9(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
if (beta != 1.0) scale_c_k9(C,M,N,LDC,beta);
double *b_buffer = (double *)aligned_alloc(4096,K_BLOCKING*N_BLOCKING*sizeof(double));
double *a_buffer = (double *)aligned_alloc(4096,K_BLOCKING*M_BLOCKING*sizeof(double));
int m_count, n_count, k_count;
int m_inc, n_inc, k_inc;
for (n_count=0;n_count<N;n_count+=n_inc){
n_inc = (N-n_count>N_BLOCKING)?N_BLOCKING:N-n_count;
for (k_count=0;k_count<K;k_count+=k_inc){
k_inc = (K-k_count>K_BLOCKING)?K_BLOCKING:K-k_count;
packing_b_k9(B+k_count+n_count*LDB,b_buffer,LDB,k_inc,n_inc);
for (m_count=0;m_count<M;m_count+=m_inc){
m_inc = (M-m_count>M_BLOCKING)?M_BLOCKING:N-m_count;
packing_a_k9(A+m_count+k_count*LDA,a_buffer,LDA,m_inc,k_inc);
//macro kernel: to compute C += A_tilt * B_tilt
macro_kernel_gemm_k9(m_inc,n_inc,k_inc,alpha,a_buffer, LDA, b_buffer, LDB, &C(m_count, n_count), LDC);
}
}
}
free(a_buffer);free(b_buffer);
}
AVX512 дозволяє перейти на блоки 24х8 тому оскільки в нас вже всьо підготовлено для макросів додаємо варіант 24х8
#define macro_kernel_24xkx8_packing_avx512_v1\
c00 = _mm512_setzero_pd();\
c01 = _mm512_setzero_pd();\
c02 = _mm512_setzero_pd();\
c10 = _mm512_setzero_pd();\
c11 = _mm512_setzero_pd();\
c12 = _mm512_setzero_pd();\
c20 = _mm512_setzero_pd();\
c21 = _mm512_setzero_pd();\
c22 = _mm512_setzero_pd();\
c30 = _mm512_setzero_pd();\
c31 = _mm512_setzero_pd();\
c32 = _mm512_setzero_pd();\
c40 = _mm512_setzero_pd();\
c41 = _mm512_setzero_pd();\
c42 = _mm512_setzero_pd();\
c50 = _mm512_setzero_pd();\
c51 = _mm512_setzero_pd();\
c52 = _mm512_setzero_pd();\
c60 = _mm512_setzero_pd();\
c61 = _mm512_setzero_pd();\
c62 = _mm512_setzero_pd();\
c70 = _mm512_setzero_pd();\
c71 = _mm512_setzero_pd();\
c72 = _mm512_setzero_pd();\
for (k=k_start;k<K4;){\
KERNEL_K1_24x8_avx512_intrinsics_packing\
KERNEL_K1_24x8_avx512_intrinsics_packing\
KERNEL_K1_24x8_avx512_intrinsics_packing\
KERNEL_K1_24x8_avx512_intrinsics_packing\
}\
for (k=K4;k<k_end;){\
KERNEL_K1_24x8_avx512_intrinsics_packing\
}\
_mm512_storeu_pd(&C(i,j), _mm512_add_pd(c00,_mm512_loadu_pd(&C(i,j))));\
_mm512_storeu_pd(&C(i+8,j), _mm512_add_pd(c01,_mm512_loadu_pd(&C(i+8,j))));\
_mm512_storeu_pd(&C(i+16,j), _mm512_add_pd(c02,_mm512_loadu_pd(&C(i+16,j))));\
_mm512_storeu_pd(&C(i,j+1), _mm512_add_pd(c10,_mm512_loadu_pd(&C(i,j+1))));\
_mm512_storeu_pd(&C(i+8,j+1), _mm512_add_pd(c11,_mm512_loadu_pd(&C(i+8,j+1))));\
_mm512_storeu_pd(&C(i+16,j+1), _mm512_add_pd(c12,_mm512_loadu_pd(&C(i+16,j+1))));\
_mm512_storeu_pd(&C(i,j+2), _mm512_add_pd(c20,_mm512_loadu_pd(&C(i,j+2))));\
_mm512_storeu_pd(&C(i+8,j+2), _mm512_add_pd(c21,_mm512_loadu_pd(&C(i+8,j+2))));\
_mm512_storeu_pd(&C(i+16,j+2), _mm512_add_pd(c22,_mm512_loadu_pd(&C(i+16,j+2))));\
_mm512_storeu_pd(&C(i,j+3), _mm512_add_pd(c30,_mm512_loadu_pd(&C(i,j+3))));\
_mm512_storeu_pd(&C(i+8,j+3), _mm512_add_pd(c31,_mm512_loadu_pd(&C(i+8,j+3))));\
_mm512_storeu_pd(&C(i+16,j+3), _mm512_add_pd(c32,_mm512_loadu_pd(&C(i+16,j+3))));\
_mm512_storeu_pd(&C(i,j+4), _mm512_add_pd(c40,_mm512_loadu_pd(&C(i,j+4))));\
_mm512_storeu_pd(&C(i+8,j+4), _mm512_add_pd(c41,_mm512_loadu_pd(&C(i+8,j+4))));\
_mm512_storeu_pd(&C(i+16,j+4), _mm512_add_pd(c42,_mm512_loadu_pd(&C(i+16,j+4))));\
_mm512_storeu_pd(&C(i,j+5), _mm512_add_pd(c50,_mm512_loadu_pd(&C(i,j+5))));\
_mm512_storeu_pd(&C(i+8,j+5), _mm512_add_pd(c51,_mm512_loadu_pd(&C(i+8,j+5))));\
_mm512_storeu_pd(&C(i+16,j+5), _mm512_add_pd(c52,_mm512_loadu_pd(&C(i+16,j+5))));\
_mm512_storeu_pd(&C(i,j+6), _mm512_add_pd(c60,_mm512_loadu_pd(&C(i,j+6))));\
_mm512_storeu_pd(&C(i+8,j+6), _mm512_add_pd(c61,_mm512_loadu_pd(&C(i+8,j+6))));\
_mm512_storeu_pd(&C(i+16,j+6), _mm512_add_pd(c62,_mm512_loadu_pd(&C(i+16,j+6))));\
_mm512_storeu_pd(&C(i,j+7), _mm512_add_pd(c70,_mm512_loadu_pd(&C(i,j+7))));\
_mm512_storeu_pd(&C(i+8,j+7), _mm512_add_pd(c71,_mm512_loadu_pd(&C(i+8,j+7))));\
_mm512_storeu_pd(&C(i+16,j+7), _mm512_add_pd(c72,_mm512_loadu_pd(&C(i+16,j+7))));
І знов слклеюємо все до купи, як бачиве тут в циклі kernel_n_4_k10 вже три варіанти, саме такі варіанти і в продакшин коді Інтела.
void macro_kernel_k10(double *a_buffer,double *b_buffer,int m,int n,int k,double *C, int LDC,double alpha){
int m_count,n_count,m_count_sub,n_count_sub;
// printf("m= %d, n=%d, k = %d\n",m,n,k);
for (n_count_sub=n,n_count=0;n_count_sub>7;n_count_sub-=8,n_count+=8){
//call the m layer with n=8;
kernel_n_8_k10(a_buffer,b_buffer+n_count*k,C+n_count*LDC,m,k,LDC,alpha);
}
for (;n_count_sub>3;n_count_sub-=4,n_count+=4){
//call the m layer with n=4
kernel_n_4_k10(a_buffer,b_buffer+n_count*k,C+n_count*LDC,m,k,LDC,alpha);
}
for (;n_count_sub>1;n_count_sub-=2,n_count+=2){
//call the m layer with n=2
}
for (;n_count_sub>0;n_count_sub-=1,n_count+=1){
//call the m layer with n=1
}
}
void mydgemm_cpu_v10(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
if (beta != 1.0) scale_c_k10(C,M,N,LDC,beta);
double *b_buffer = (double *)aligned_alloc(4096,K_BLOCKING*N_BLOCKING*sizeof(double));
double *a_buffer = (double *)aligned_alloc(4096,K_BLOCKING*M_BLOCKING*sizeof(double));
int m_count, n_count, k_count;
int m_inc, n_inc, k_inc;
for (n_count=0;n_count<N;n_count+=n_inc){
n_inc = (N-n_count>N_BLOCKING)?N_BLOCKING:N-n_count;
for (k_count=0;k_count<K;k_count+=k_inc){
k_inc = (K-k_count>K_BLOCKING)?K_BLOCKING:K-k_count;
packing_b_k10(B+k_count+n_count*LDB,b_buffer,LDB,k_inc,n_inc);
for (m_count=0;m_count<M;m_count+=m_inc){
m_inc = (M-m_count>M_BLOCKING)?M_BLOCKING:N-m_count;
packing_a_k10(A+m_count+k_count*LDA,a_buffer,LDA,m_inc,k_inc);
//macro kernel: to compute C += A_tilt * B_tilt
macro_kernel_k10(a_buffer, b_buffer, m_inc, n_inc, k_inc, &C(m_count, n_count), LDC, alpha);
}
}
}
free(a_buffer);free(b_buffer);
}
Йдемо далі! Ми робила пакінг в неперервну пам'ять, але оскільки кеш TLB процесора влаштований інакше ніж лінійна пам'ять і має рядки, нам необхідно врахувати це і перепеписати серіалізація матриць. Ми можемо знехтувати неперевність представлення в пам'яті матриці B і за допомогою префетчів сховати латенсі. Зауважте різницю А і B варіантів.
void packing_a_k11(double *src, double *dst, int leading_dim, int dim_first, int dim_second){
//dim_first: M, dim_second: K
double *tosrc,*todst;
todst=dst;
int count_first,count_second,count_sub=dim_first;
for (count_first=0;count_sub>23;count_first+=24,count_sub-=24){
tosrc=src+count_first;
for(count_second=0;count_second<dim_second;count_second++){
_mm512_store_pd(todst,_mm512_loadu_pd(tosrc));
_mm512_store_pd(todst+8,_mm512_loadu_pd(tosrc+8));
_mm512_store_pd(todst+16,_mm512_loadu_pd(tosrc+16));
tosrc+=leading_dim;
todst+=24;
}
}
// edge case
for (;count_sub>7;count_first+=8,count_sub-=8){
tosrc=src+count_first;
for(count_second=0;count_second<dim_second;count_second++){
_mm512_store_pd(todst,_mm512_loadu_pd(tosrc));
tosrc+=leading_dim;
todst+=8;
}
}
for (;count_sub>1;count_first+=2,count_sub-=2){
tosrc=src+count_first;
for(count_second=0;count_second<dim_second;count_second++){
_mm_store_pd(todst,_mm_loadu_pd(tosrc));
tosrc+=leading_dim;
todst+=2;
}
}
for (;count_sub>0;count_first+=1,count_sub-=1){
tosrc=src+count_first;
for(count_second=0;count_second<dim_second;count_second++){
*todst=*tosrc;
tosrc+=leading_dim;
todst++;
}
}
}
void packing_b_k11(double *src,double *dst,int leading_dim,int dim_first,int dim_second){
//dim_first:K,dim_second:N
double *tosrc1,*tosrc2,*todst;
todst=dst;
int count_first,count_second,count_sub=dim_second;
for (count_second=0;count_sub>1;count_second+=2,count_sub-=2){
tosrc1=src+count_second*leading_dim;tosrc2=tosrc1+leading_dim;
for (count_first=0;count_first<dim_first;count_first++){
*todst=*tosrc1;tosrc1++;todst++;
*todst=*tosrc2;tosrc2++;todst++;
}
}
for (;count_sub>0;count_second++,count_sub-=1){
tosrc1=src+count_second*leading_dim;
for (count_first=0;count_first<dim_first;count_first++){
*todst=*tosrc1;tosrc1++;todst++;
}
}
}
Залишилося тільки розставити prefetch інструкції для того шоб догнати Intel MKL бібліотеку. Кінцевий варіант виглядає так:
#define KERNEL_K1_24x8_avx512_intrinsics_packing_v2\
a0 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a));\
a1 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a+8));\
a2 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a+16));\
b0 = _mm512_set1_pd(*ptr_packing_b0);\
b1 = _mm512_set1_pd(*(ptr_packing_b0+1));\
c00 = _mm512_fmadd_pd(a0,b0,c00);\
c01 = _mm512_fmadd_pd(a1,b0,c01);\
c02 = _mm512_fmadd_pd(a2,b0,c02);\
c10 = _mm512_fmadd_pd(a0,b1,c10);\
c11 = _mm512_fmadd_pd(a1,b1,c11);\
c12 = _mm512_fmadd_pd(a2,b1,c12);\
b0 = _mm512_set1_pd(*(ptr_packing_b1));\
b1 = _mm512_set1_pd(*(ptr_packing_b1+1));\
c20 = _mm512_fmadd_pd(a0,b0,c20);\
c21 = _mm512_fmadd_pd(a1,b0,c21);\
c22 = _mm512_fmadd_pd(a2,b0,c22);\
c30 = _mm512_fmadd_pd(a0,b1,c30);\
c31 = _mm512_fmadd_pd(a1,b1,c31);\
c32 = _mm512_fmadd_pd(a2,b1,c32);\
b0 = _mm512_set1_pd(*(ptr_packing_b2));\
b1 = _mm512_set1_pd(*(ptr_packing_b2+1));\
c40 = _mm512_fmadd_pd(a0,b0,c40);\
c41 = _mm512_fmadd_pd(a1,b0,c41);\
c42 = _mm512_fmadd_pd(a2,b0,c42);\
c50 = _mm512_fmadd_pd(a0,b1,c50);\
c51 = _mm512_fmadd_pd(a1,b1,c51);\
c52 = _mm512_fmadd_pd(a2,b1,c52);\
b0 = _mm512_set1_pd(*(ptr_packing_b3));\
b1 = _mm512_set1_pd(*(ptr_packing_b3+1));\
c60 = _mm512_fmadd_pd(a0,b0,c60);\
c61 = _mm512_fmadd_pd(a1,b0,c61);\
c62 = _mm512_fmadd_pd(a2,b0,c62);\
c70 = _mm512_fmadd_pd(a0,b1,c70);\
c71 = _mm512_fmadd_pd(a1,b1,c71);\
c72 = _mm512_fmadd_pd(a2,b1,c72);\
ptr_packing_b0+=2;ptr_packing_b1+=2;ptr_packing_b2+=2;ptr_packing_b3+=2;\
ptr_packing_a+=24;k++;
#define macro_kernel_24xkx8_packing_avx512_v2\
c00 = _mm512_setzero_pd();\
c01 = _mm512_setzero_pd();\
c02 = _mm512_setzero_pd();\
c10 = _mm512_setzero_pd();\
c11 = _mm512_setzero_pd();\
c12 = _mm512_setzero_pd();\
c20 = _mm512_setzero_pd();\
c21 = _mm512_setzero_pd();\
c22 = _mm512_setzero_pd();\
c30 = _mm512_setzero_pd();\
c31 = _mm512_setzero_pd();\
c32 = _mm512_setzero_pd();\
c40 = _mm512_setzero_pd();\
c41 = _mm512_setzero_pd();\
c42 = _mm512_setzero_pd();\
c50 = _mm512_setzero_pd();\
c51 = _mm512_setzero_pd();\
c52 = _mm512_setzero_pd();\
c60 = _mm512_setzero_pd();\
c61 = _mm512_setzero_pd();\
c62 = _mm512_setzero_pd();\
c70 = _mm512_setzero_pd();\
c71 = _mm512_setzero_pd();\
c72 = _mm512_setzero_pd();\
for (k=k_start;k<K4;){\
KERNEL_K1_24x8_avx512_intrinsics_packing_v2\
KERNEL_K1_24x8_avx512_intrinsics_packing_v2\
KERNEL_K1_24x8_avx512_intrinsics_packing_v2\
KERNEL_K1_24x8_avx512_intrinsics_packing_v2\
}\
for (k=K4;k<k_end;){\
KERNEL_K1_24x8_avx512_intrinsics_packing_v2\
}\
_mm512_storeu_pd(&C(i,j), _mm512_add_pd(c00,_mm512_loadu_pd(&C(i,j))));\
_mm512_storeu_pd(&C(i+8,j), _mm512_add_pd(c01,_mm512_loadu_pd(&C(i+8,j))));\
_mm512_storeu_pd(&C(i+16,j), _mm512_add_pd(c02,_mm512_loadu_pd(&C(i+16,j))));\
_mm512_storeu_pd(&C(i,j+1), _mm512_add_pd(c10,_mm512_loadu_pd(&C(i,j+1))));\
_mm512_storeu_pd(&C(i+8,j+1), _mm512_add_pd(c11,_mm512_loadu_pd(&C(i+8,j+1))));\
_mm512_storeu_pd(&C(i+16,j+1), _mm512_add_pd(c12,_mm512_loadu_pd(&C(i+16,j+1))));\
_mm512_storeu_pd(&C(i,j+2), _mm512_add_pd(c20,_mm512_loadu_pd(&C(i,j+2))));\
_mm512_storeu_pd(&C(i+8,j+2), _mm512_add_pd(c21,_mm512_loadu_pd(&C(i+8,j+2))));\
_mm512_storeu_pd(&C(i+16,j+2), _mm512_add_pd(c22,_mm512_loadu_pd(&C(i+16,j+2))));\
_mm512_storeu_pd(&C(i,j+3), _mm512_add_pd(c30,_mm512_loadu_pd(&C(i,j+3))));\
_mm512_storeu_pd(&C(i+8,j+3), _mm512_add_pd(c31,_mm512_loadu_pd(&C(i+8,j+3))));\
_mm512_storeu_pd(&C(i+16,j+3), _mm512_add_pd(c32,_mm512_loadu_pd(&C(i+16,j+3))));\
_mm512_storeu_pd(&C(i,j+4), _mm512_add_pd(c40,_mm512_loadu_pd(&C(i,j+4))));\
_mm512_storeu_pd(&C(i+8,j+4), _mm512_add_pd(c41,_mm512_loadu_pd(&C(i+8,j+4))));\
_mm512_storeu_pd(&C(i+16,j+4), _mm512_add_pd(c42,_mm512_loadu_pd(&C(i+16,j+4))));\
_mm512_storeu_pd(&C(i,j+5), _mm512_add_pd(c50,_mm512_loadu_pd(&C(i,j+5))));\
_mm512_storeu_pd(&C(i+8,j+5), _mm512_add_pd(c51,_mm512_loadu_pd(&C(i+8,j+5))));\
_mm512_storeu_pd(&C(i+16,j+5), _mm512_add_pd(c52,_mm512_loadu_pd(&C(i+16,j+5))));\
_mm512_storeu_pd(&C(i,j+6), _mm512_add_pd(c60,_mm512_loadu_pd(&C(i,j+6))));\
_mm512_storeu_pd(&C(i+8,j+6), _mm512_add_pd(c61,_mm512_loadu_pd(&C(i+8,j+6))));\
_mm512_storeu_pd(&C(i+16,j+6), _mm512_add_pd(c62,_mm512_loadu_pd(&C(i+16,j+6))));\
_mm512_storeu_pd(&C(i,j+7), _mm512_add_pd(c70,_mm512_loadu_pd(&C(i,j+7))));\
_mm512_storeu_pd(&C(i+8,j+7), _mm512_add_pd(c71,_mm512_loadu_pd(&C(i+8,j+7))));\
_mm512_storeu_pd(&C(i+16,j+7), _mm512_add_pd(c72,_mm512_loadu_pd(&C(i+16,j+7))));
#define KERNEL_K1_8x8_avx512_intrinsics_packing_v2\
a0 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a));\
b0 = _mm512_set1_pd(*ptr_packing_b0);\
b1 = _mm512_set1_pd(*(ptr_packing_b0+1));\
c00 = _mm512_fmadd_pd(a0,b0,c00);\
c10 = _mm512_fmadd_pd(a0,b1,c10);\
b0 = _mm512_set1_pd(*(ptr_packing_b1));\
b1 = _mm512_set1_pd(*(ptr_packing_b1+1));\
c20 = _mm512_fmadd_pd(a0,b0,c20);\
c30 = _mm512_fmadd_pd(a0,b1,c30);\
b0 = _mm512_set1_pd(*(ptr_packing_b2));\
b1 = _mm512_set1_pd(*(ptr_packing_b2+1));\
c40 = _mm512_fmadd_pd(a0,b0,c40);\
c50 = _mm512_fmadd_pd(a0,b1,c50);\
b0 = _mm512_set1_pd(*(ptr_packing_b3));\
b1 = _mm512_set1_pd(*(ptr_packing_b3+1));\
c60 = _mm512_fmadd_pd(a0,b0,c60);\
c70 = _mm512_fmadd_pd(a0,b1,c70);\
ptr_packing_b0+=2;ptr_packing_b1+=2;ptr_packing_b2+=2;ptr_packing_b3+=2;\
ptr_packing_a+=8;k++;
#define macro_kernel_8xkx8_packing_avx512_v2\
c00 = _mm512_setzero_pd();\
c10 = _mm512_setzero_pd();\
c20 = _mm512_setzero_pd();\
c30 = _mm512_setzero_pd();\
c40 = _mm512_setzero_pd();\
c50 = _mm512_setzero_pd();\
c60 = _mm512_setzero_pd();\
c70 = _mm512_setzero_pd();\
for (k=k_start;k<K4;){\
KERNEL_K1_8x8_avx512_intrinsics_packing_v2\
KERNEL_K1_8x8_avx512_intrinsics_packing_v2\
KERNEL_K1_8x8_avx512_intrinsics_packing_v2\
KERNEL_K1_8x8_avx512_intrinsics_packing_v2\
}\
for (k=K4;k<k_end;){\
KERNEL_K1_8x8_avx512_intrinsics_packing_v2\
}\
_mm512_storeu_pd(&C(i,j), _mm512_add_pd(c00,_mm512_loadu_pd(&C(i,j))));\
_mm512_storeu_pd(&C(i,j+1), _mm512_add_pd(c10,_mm512_loadu_pd(&C(i,j+1))));\
_mm512_storeu_pd(&C(i,j+2), _mm512_add_pd(c20,_mm512_loadu_pd(&C(i,j+2))));\
_mm512_storeu_pd(&C(i,j+3), _mm512_add_pd(c30,_mm512_loadu_pd(&C(i,j+3))));\
_mm512_storeu_pd(&C(i,j+4), _mm512_add_pd(c40,_mm512_loadu_pd(&C(i,j+4))));\
_mm512_storeu_pd(&C(i,j+5), _mm512_add_pd(c50,_mm512_loadu_pd(&C(i,j+5))));\
_mm512_storeu_pd(&C(i,j+6), _mm512_add_pd(c60,_mm512_loadu_pd(&C(i,j+6))));\
_mm512_storeu_pd(&C(i,j+7), _mm512_add_pd(c70,_mm512_loadu_pd(&C(i,j+7))));
#define KERNEL_K1_2x8_avx512_intrinsics_packing_v2\
da0 = _mm_mul_pd(dvalpha, _mm_load_pd(ptr_packing_a));\
db0 = _mm_set1_pd(*ptr_packing_b0);\
db1 = _mm_set1_pd(*(ptr_packing_b0+1));\
dc00 = _mm_fmadd_pd(da0,db0,dc00);\
dc10 = _mm_fmadd_pd(da0,db1,dc10);\
db0 = _mm_set1_pd(*(ptr_packing_b1));\
db1 = _mm_set1_pd(*(ptr_packing_b1+1));\
dc20 = _mm_fmadd_pd(da0,db0,dc20);\
dc30 = _mm_fmadd_pd(da0,db1,dc30);\
db0 = _mm_set1_pd(*(ptr_packing_b2));\
db1 = _mm_set1_pd(*(ptr_packing_b2+1));\
dc40 = _mm_fmadd_pd(da0,db0,dc40);\
dc50 = _mm_fmadd_pd(da0,db1,dc50);\
db0 = _mm_set1_pd(*(ptr_packing_b3));\
db1 = _mm_set1_pd(*(ptr_packing_b3+1));\
dc60 = _mm_fmadd_pd(da0,db0,dc60);\
dc70 = _mm_fmadd_pd(da0,db1,dc70);\
ptr_packing_b0+=2;ptr_packing_b1+=2;ptr_packing_b2+=2;ptr_packing_b3+=2;\
ptr_packing_a+=2;k++;
#define macro_kernel_2xkx8_packing_avx512_v2\
dc00 = _mm_setzero_pd();\
dc10 = _mm_setzero_pd();\
dc20 = _mm_setzero_pd();\
dc30 = _mm_setzero_pd();\
dc40 = _mm_setzero_pd();\
dc50 = _mm_setzero_pd();\
dc60 = _mm_setzero_pd();\
dc70 = _mm_setzero_pd();\
for (k=k_start;k<K4;){\
KERNEL_K1_2x8_avx512_intrinsics_packing_v2\
KERNEL_K1_2x8_avx512_intrinsics_packing_v2\
KERNEL_K1_2x8_avx512_intrinsics_packing_v2\
KERNEL_K1_2x8_avx512_intrinsics_packing_v2\
}\
for (k=K4;k<k_end;){\
KERNEL_K1_2x8_avx512_intrinsics_packing_v2\
}\
_mm_storeu_pd(&C(i,j), _mm_add_pd(dc00,_mm_loadu_pd(&C(i,j))));\
_mm_storeu_pd(&C(i,j+1), _mm_add_pd(dc10,_mm_loadu_pd(&C(i,j+1))));\
_mm_storeu_pd(&C(i,j+2), _mm_add_pd(dc20,_mm_loadu_pd(&C(i,j+2))));\
_mm_storeu_pd(&C(i,j+3), _mm_add_pd(dc30,_mm_loadu_pd(&C(i,j+3))));\
_mm_storeu_pd(&C(i,j+4), _mm_add_pd(dc40,_mm_loadu_pd(&C(i,j+4))));\
_mm_storeu_pd(&C(i,j+5), _mm_add_pd(dc50,_mm_loadu_pd(&C(i,j+5))));\
_mm_storeu_pd(&C(i,j+6), _mm_add_pd(dc60,_mm_loadu_pd(&C(i,j+6))));\
_mm_storeu_pd(&C(i,j+7), _mm_add_pd(dc70,_mm_loadu_pd(&C(i,j+7))));
#define macro_packing_kernel_1xkx8_v2\
sc0=sc1=sc2=sc3=sc4=sc5=sc6=sc7=0.;\
for (k=k_start;k<k_end;k++){\
sa=alpha*(*ptr_packing_a);\
sb0=*(ptr_packing_b0);sb1=*(ptr_packing_b0+1);sb2=*(ptr_packing_b1);sb3=*(ptr_packing_b1+1);\
sb4=*(ptr_packing_b2);sb5=*(ptr_packing_b2+1);sb6=*(ptr_packing_b3);sb7=*(ptr_packing_b3+1);\
sc0+=sa*sb0;sc1+=sa*sb1;sc2+=sa*sb2;sc3+=sa*sb3;\
sc4+=sa*sb4;sc5+=sa*sb5;sc6+=sa*sb6;sc7+=sa*sb7;\
ptr_packing_a++;ptr_packing_b0+=2;\
ptr_packing_b1+=2;ptr_packing_b2+=2;ptr_packing_b3+=2;\
}\
C(i,j)+=sc0;C(i,j+1)+=sc1;C(i,j+2)+=sc2;C(i,j+3)+=sc3;\
C(i,j+4)+=sc4;C(i,j+5)+=sc5;C(i,j+6)+=sc6;C(i,j+7)+=sc7;
#define KERNEL_K1_24x4_avx512_intrinsics_packing_v2\
a0 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a));\
a1 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a+8));\
a2 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a+16));\
b0 = _mm512_set1_pd(*ptr_packing_b0);\
b1 = _mm512_set1_pd(*(ptr_packing_b0+1));\
c00 = _mm512_fmadd_pd(a0,b0,c00);\
c01 = _mm512_fmadd_pd(a1,b0,c01);\
c02 = _mm512_fmadd_pd(a2,b0,c02);\
c10 = _mm512_fmadd_pd(a0,b1,c10);\
c11 = _mm512_fmadd_pd(a1,b1,c11);\
c12 = _mm512_fmadd_pd(a2,b1,c12);\
b0 = _mm512_set1_pd(*(ptr_packing_b1));\
b1 = _mm512_set1_pd(*(ptr_packing_b1+1));\
c20 = _mm512_fmadd_pd(a0,b0,c20);\
c21 = _mm512_fmadd_pd(a1,b0,c21);\
c22 = _mm512_fmadd_pd(a2,b0,c22);\
c30 = _mm512_fmadd_pd(a0,b1,c30);\
c31 = _mm512_fmadd_pd(a1,b1,c31);\
c32 = _mm512_fmadd_pd(a2,b1,c32);\
ptr_packing_a+=24;ptr_packing_b0+=2;ptr_packing_b1+=2;k++;
#define macro_kernel_24xkx4_packing_avx512_v2\
c00 = _mm512_setzero_pd();\
c01 = _mm512_setzero_pd();\
c02 = _mm512_setzero_pd();\
c10 = _mm512_setzero_pd();\
c11 = _mm512_setzero_pd();\
c12 = _mm512_setzero_pd();\
c20 = _mm512_setzero_pd();\
c21 = _mm512_setzero_pd();\
c22 = _mm512_setzero_pd();\
c30 = _mm512_setzero_pd();\
c31 = _mm512_setzero_pd();\
c32 = _mm512_setzero_pd();\
for (k=k_start;k<K4;){\
KERNEL_K1_24x4_avx512_intrinsics_packing_v2\
KERNEL_K1_24x4_avx512_intrinsics_packing_v2\
KERNEL_K1_24x4_avx512_intrinsics_packing_v2\
KERNEL_K1_24x4_avx512_intrinsics_packing_v2\
}\
for (k=K4;k<k_end;){\
KERNEL_K1_24x4_avx512_intrinsics_packing_v2\
}\
_mm512_storeu_pd(&C(i,j), _mm512_add_pd(c00,_mm512_loadu_pd(&C(i,j))));\
_mm512_storeu_pd(&C(i+8,j), _mm512_add_pd(c01,_mm512_loadu_pd(&C(i+8,j))));\
_mm512_storeu_pd(&C(i+16,j), _mm512_add_pd(c02,_mm512_loadu_pd(&C(i+16,j))));\
_mm512_storeu_pd(&C(i,j+1), _mm512_add_pd(c10,_mm512_loadu_pd(&C(i,j+1))));\
_mm512_storeu_pd(&C(i+8,j+1), _mm512_add_pd(c11,_mm512_loadu_pd(&C(i+8,j+1))));\
_mm512_storeu_pd(&C(i+16,j+1), _mm512_add_pd(c12,_mm512_loadu_pd(&C(i+16,j+1))));\
_mm512_storeu_pd(&C(i,j+2), _mm512_add_pd(c20,_mm512_loadu_pd(&C(i,j+2))));\
_mm512_storeu_pd(&C(i+8,j+2), _mm512_add_pd(c21,_mm512_loadu_pd(&C(i+8,j+2))));\
_mm512_storeu_pd(&C(i+16,j+2), _mm512_add_pd(c22,_mm512_loadu_pd(&C(i+16,j+2))));\
_mm512_storeu_pd(&C(i,j+3), _mm512_add_pd(c30,_mm512_loadu_pd(&C(i,j+3))));\
_mm512_storeu_pd(&C(i+8,j+3), _mm512_add_pd(c31,_mm512_loadu_pd(&C(i+8,j+3))));\
_mm512_storeu_pd(&C(i+16,j+3), _mm512_add_pd(c32,_mm512_loadu_pd(&C(i+16,j+3))));
#define KERNEL_K1_4x8_avx512_intrinsics_packing_v2\
a0 = _mm512_mul_pd(valpha, _mm512_load_pd(ptr_packing_a));\
b0 = _mm512_set1_pd(*ptr_packing_b0);\
b1 = _mm512_set1_pd(*(ptr_packing_b0+1));\
c00 = _mm512_fmadd_pd(a0,b0,c00);\
c10 = _mm512_fmadd_pd(a0,b1,c10);\
b0 = _mm512_set1_pd(*(ptr_packing_b1));\
b1 = _mm512_set1_pd(*(ptr_packing_b1+1));\
c20 = _mm512_fmadd_pd(a0,b0,c20);\
c30 = _mm512_fmadd_pd(a0,b1,c30);\
ptr_packing_a+=8;ptr_packing_b0+=2;ptr_packing_b1+=2;k++;
#define macro_kernel_8xkx4_packing_avx512_v2\
c00 = _mm512_setzero_pd();\
c10 = _mm512_setzero_pd();\
c20 = _mm512_setzero_pd();\
c30 = _mm512_setzero_pd();\
for (k=k_start;k<K4;){\
KERNEL_K1_4x8_avx512_intrinsics_packing_v2\
KERNEL_K1_4x8_avx512_intrinsics_packing_v2\
KERNEL_K1_4x8_avx512_intrinsics_packing_v2\
KERNEL_K1_4x8_avx512_intrinsics_packing_v2\
}\
for (k=K4;k<k_end;){\
KERNEL_K1_4x8_avx512_intrinsics_packing_v2\
}\
_mm512_storeu_pd(&C(i,j), _mm512_add_pd(c00,_mm512_loadu_pd(&C(i,j))));\
_mm512_storeu_pd(&C(i,j+1), _mm512_add_pd(c10,_mm512_loadu_pd(&C(i,j+1))));\
_mm512_storeu_pd(&C(i,j+2), _mm512_add_pd(c20,_mm512_loadu_pd(&C(i,j+2))));\
_mm512_storeu_pd(&C(i,j+3), _mm512_add_pd(c30,_mm512_loadu_pd(&C(i,j+3))));
#define KERNEL_K1_2x4_avx512_intrinsics_packing_v2\
da0 = _mm_mul_pd(dvalpha, _mm_load_pd(ptr_packing_a));\
db0 = _mm_set1_pd(*ptr_packing_b0);\
db1 = _mm_set1_pd(*(ptr_packing_b0+1));\
dc00 = _mm_fmadd_pd(da0,db0,dc00);\
dc10 = _mm_fmadd_pd(da0,db1,dc10);\
db0 = _mm_set1_pd(*(ptr_packing_b1));\
db1 = _mm_set1_pd(*(ptr_packing_b1+1));\
dc20 = _mm_fmadd_pd(da0,db0,dc20);\
dc30 = _mm_fmadd_pd(da0,db1,dc30);\
ptr_packing_a+=2;ptr_packing_b0+=2;ptr_packing_b1+=2;k++;
#define macro_kernel_2xkx4_packing_avx512_v2\
dc00 = _mm_setzero_pd();\
dc10 = _mm_setzero_pd();\
dc20 = _mm_setzero_pd();\
dc30 = _mm_setzero_pd();\
for (k=k_start;k<K4;){\
KERNEL_K1_2x4_avx512_intrinsics_packing_v2\
KERNEL_K1_2x4_avx512_intrinsics_packing_v2\
KERNEL_K1_2x4_avx512_intrinsics_packing_v2\
KERNEL_K1_2x4_avx512_intrinsics_packing_v2\
}\
for (k=K4;k<k_end;){\
KERNEL_K1_2x4_avx512_intrinsics_packing_v2\
}\
_mm_storeu_pd(&C(i,j), _mm_add_pd(dc00,_mm_loadu_pd(&C(i,j))));\
_mm_storeu_pd(&C(i,j+1), _mm_add_pd(dc10,_mm_loadu_pd(&C(i,j+1))));\
_mm_storeu_pd(&C(i,j+2), _mm_add_pd(dc20,_mm_loadu_pd(&C(i,j+2))));\
_mm_storeu_pd(&C(i,j+3), _mm_add_pd(dc30,_mm_loadu_pd(&C(i,j+3))));
void kernel_n_8_v2_k11(double *a_buffer,double *b_buffer,double *c_ptr,int m,int K,int LDC,double alpha){
int m_count,m_count_sub;
int i,j,k;
double *C=c_ptr;
double sc0,sc1,sc2,sc3,sc4,sc5,sc6,sc7,sa,sb0,sb1,sb2,sb3,sb4,sb5,sb6,sb7;
__m128d da,da0,da1,da2,db0,db1,db2,db3;
__m128d dc00,dc10,dc20,dc30,dc40,dc50,dc60,dc70;
__m512d valpha = _mm512_set1_pd(alpha);//broadcast alpha to a 512-bit vector
__m128d dvalpha = _mm_set1_pd(alpha);//broadcast alpha to a 128-bit vector
__m512d a,a0,a1,a2,b0,b1,b2,b3;
__m512d c00,c01,c02,c10,c11,c12,c20,c21,c22,c30,c31,c32,c40,c41,c42,c50,c51,c52,c60,c61,c62,c70,c71,c72;
__m512d c0,c1,c2,c3;
double *ptr_packing_a,*ptr_packing_b0,*ptr_packing_b1,*ptr_packing_b2,*ptr_packing_b3;
int k_start,k_end,K4;
K4=K&-4;k_end=K;k_start=0;
// printf("*****\n");
// print_matrix(C,m,8);
// printf("*****\n");
for (m_count_sub=m,m_count=0;m_count_sub>23;m_count_sub-=24,m_count+=24){
//call the micro kernel: m24n8;
i=m_count;j=0;ptr_packing_a=a_buffer+m_count*K;
ptr_packing_b0=b_buffer;ptr_packing_b1=ptr_packing_b0+2*K;
ptr_packing_b2=ptr_packing_b1+2*K;ptr_packing_b3=ptr_packing_b2+2*K;
macro_kernel_24xkx8_packing_avx512_v2
}
for (;m_count_sub>7;m_count_sub-=8,m_count+=8){
//call the micro kernel: m8n8;
i=m_count;j=0;ptr_packing_a=a_buffer+m_count*K;
ptr_packing_b0=b_buffer;ptr_packing_b1=ptr_packing_b0+2*K;
ptr_packing_b2=ptr_packing_b1+2*K;ptr_packing_b3=ptr_packing_b2+2*K;
macro_kernel_8xkx8_packing_avx512_v2
}
for (;m_count_sub>1;m_count_sub-=2,m_count+=2){
//call the micro kernel: m2n8;
i=m_count;j=0;ptr_packing_a=a_buffer+m_count*K;
ptr_packing_b0=b_buffer;ptr_packing_b1=ptr_packing_b0+2*K;
ptr_packing_b2=ptr_packing_b1+2*K;ptr_packing_b3=ptr_packing_b2+2*K;
macro_kernel_2xkx8_packing_avx512_v2
}
for (;m_count_sub>0;m_count_sub-=1,m_count+=1){
//call the micro kernel: m1n8;
i=m_count;j=0;ptr_packing_a=a_buffer+m_count*K;
ptr_packing_b0=b_buffer;ptr_packing_b1=ptr_packing_b0+2*K;
ptr_packing_b2=ptr_packing_b1+2*K;ptr_packing_b3=ptr_packing_b2+2*K;
macro_packing_kernel_1xkx8_v2
}
}
void kernel_n_4_v2_k11(double *a_buffer,double *b_buffer,double *c_ptr,int m,int K,int LDC,double alpha){
int m_count,m_count_sub;
int i,j,k;
double *C=c_ptr;
double sc0,sc1,sc2,sc3,sc4,sc5,sc6,sc7,sa,sb0,sb1,sb2,sb3,sb4,sb5,sb6,sb7;
__m128d da,da0,da1,da2,db0,db1,db2,db3;
__m128d dc00,dc10,dc20,dc30,dc40,dc50,dc60,dc70;
__m512d valpha = _mm512_set1_pd(alpha);//broadcast alpha to a 512-bit vector
__m128d dvalpha = _mm_set1_pd(alpha);//broadcast alpha to a 128-bit vector
__m512d a,a0,a1,a2,b0,b1,b2,b3;
__m512d c00,c01,c02,c10,c11,c12,c20,c21,c22,c30,c31,c32,c40,c41,c42,c50,c51,c52,c60,c61,c62,c70,c71,c72;
__m512d c0,c1,c2,c3;
double *ptr_packing_a,*ptr_packing_b0,*ptr_packing_b1,*ptr_packing_b2,*ptr_packing_b3;
int k_start,k_end,K4;
K4=K&-4;k_end=K;k_start=0;
for (m_count_sub=m,m_count=0;m_count_sub>23;m_count_sub-=24,m_count+=24){
//call the micro kernel: m24n4;
i=m_count;j=0;ptr_packing_a=a_buffer+m_count*K;
ptr_packing_b0=b_buffer;ptr_packing_b1=ptr_packing_b0+2*K;
macro_kernel_24xkx4_packing_avx512_v2
}
for (;m_count_sub>7;m_count_sub-=8,m_count+=8){
//call the micro kernel: m8n4;
i=m_count;j=0;ptr_packing_a=a_buffer+m_count*K;
ptr_packing_b0=b_buffer;ptr_packing_b1=ptr_packing_b0+2*K;
macro_kernel_8xkx4_packing_avx512_v2
}
for (;m_count_sub>1;m_count_sub-=2,m_count+=2){
//call the micro kernel: m2n4;
i=m_count;j=0;ptr_packing_a=a_buffer+m_count*K;
ptr_packing_b0=b_buffer;ptr_packing_b1=ptr_packing_b0+2*K;
macro_kernel_2xkx4_packing_avx512_v2
}
for (;m_count_sub>0;m_count_sub-=1,m_count+=1){
//call the micro kernel: m1n4;
}
}
void macro_kernel_k11(double *a_buffer,double *b_buffer,int m,int n,int k,double *C, int LDC,double alpha){
int m_count,n_count,m_count_sub,n_count_sub;
// printf("m= %d, n=%d, k = %d\n",m,n,k);
for (n_count_sub=n,n_count=0;n_count_sub>7;n_count_sub-=8,n_count+=8){
//call the m layer with n=8;
kernel_n_8_v2_k11(a_buffer,b_buffer+n_count*k,C+n_count*LDC,m,k,LDC,alpha);
}
for (;n_count_sub>3;n_count_sub-=4,n_count+=4){
//call the m layer with n=4
kernel_n_4_v2_k11(a_buffer,b_buffer+n_count*k,C+n_count*LDC,m,k,LDC,alpha);
}
for (;n_count_sub>1;n_count_sub-=2,n_count+=2){
//call the m layer with n=2
}
for (;n_count_sub>0;n_count_sub-=1,n_count+=1){
//call the m layer with n=1
}
}
void mydgemm_cpu_v11(int M, int N, int K, double alpha, double *A, int LDA, double *B, int LDB, double beta, double *C, int LDC){
if (beta != 1.0) scale_c_k11(C,M,N,LDC,beta);
double *b_buffer = (double *)aligned_alloc(4096,K_BLOCKING*N_BLOCKING*sizeof(double));
double *a_buffer = (double *)aligned_alloc(4096,K_BLOCKING*M_BLOCKING*sizeof(double));
int m_count, n_count, k_count;
int m_inc, n_inc, k_inc;
for (n_count=0;n_countN_BLOCKING)?N_BLOCKING:N-n_count;
for (k_count=0;k_countK_BLOCKING)?K_BLOCKING:K-k_count;
packing_b_k11(B+k_count+n_count*LDB,b_buffer,LDB,k_inc,n_inc);
for (m_count=0;m_countM_BLOCKING)?M_BLOCKING:N-m_count;
packing_a_k11(A+m_count+k_count*LDA,a_buffer,LDA,m_inc,k_inc);
//macro kernel: to compute C += A_tilt * B_tilt
macro_kernel_k11(a_buffer, b_buffer, m_inc, n_inc, k_inc, &C(m_count, n_count), LDC, alpha);
}
}
}
free(a_buffer);free(b_buffer);
}
Тобто ця штука, на матрицях розміру більше 1600 починає бути швидшою навіть за Intel MKL. Шоб перевірити треба мати AVX512 від Intel.
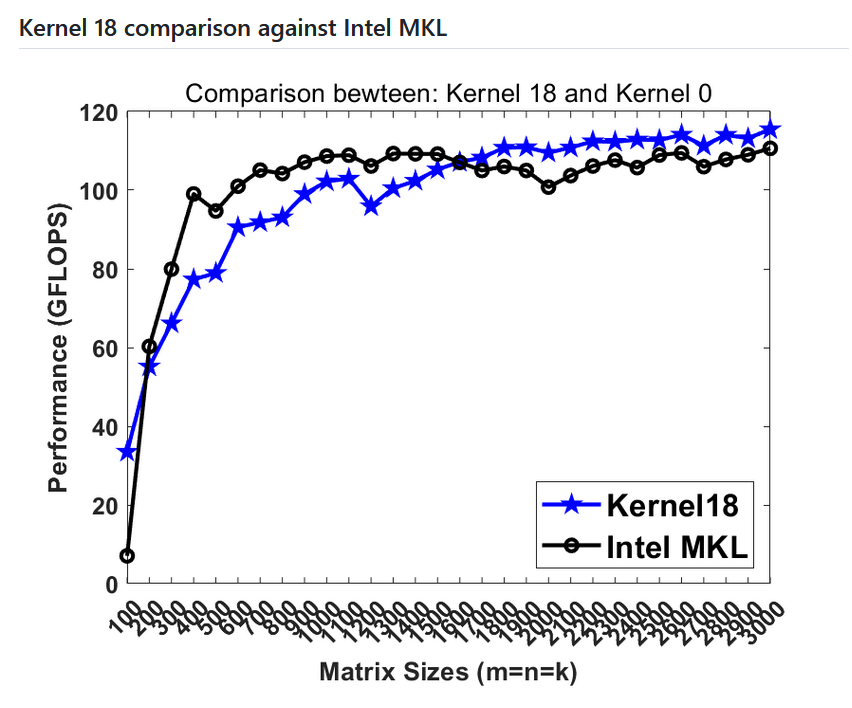
AVX2 на i7-8700 дає 64 GFLOPS, а AVX512 на i9-10980XE — 100 GFLOPS.